

#18 The Case for Open Source AI Models
Plus: many AI releases, AI model collapse, data quality and AI, AI fatigue, and more

👋 Welcome back to "AI Simplified for Leaders," your bi-weekly digest aimed at making sense of artificial intelligence for business leaders, board members, and investors. I invite you to check out past issues through this link.
In this issue, I cover:
Notable News: many frontier AI model releases, xAI’s Memphis AI supercluster, OpenAI’s SearchGPT, scientists and practitioners disagree on ‘AI model collapse’
The Case for Open Source AI Models, with Model Distillation 101
Data Quality and AI
One More Thing: shake off the AI fatigue
Enjoy.
Notable News
1. Many Frontier AI Model Releases: Quality vs Cost
It has been a busy two-week period when it comes to the frontier of AI foundational model releases. OpenAI has unveiled GPT-4o Mini, a cost-efficient and powerful small AI model aimed at expanding AI accessibility. Mistral released Mistral Large 2, significantly more capable than previous generation in code generation, mathematics, and reasoning. Meta released the highly anticipated Llama3 405B model, pulling forward the close source AI model advancements.
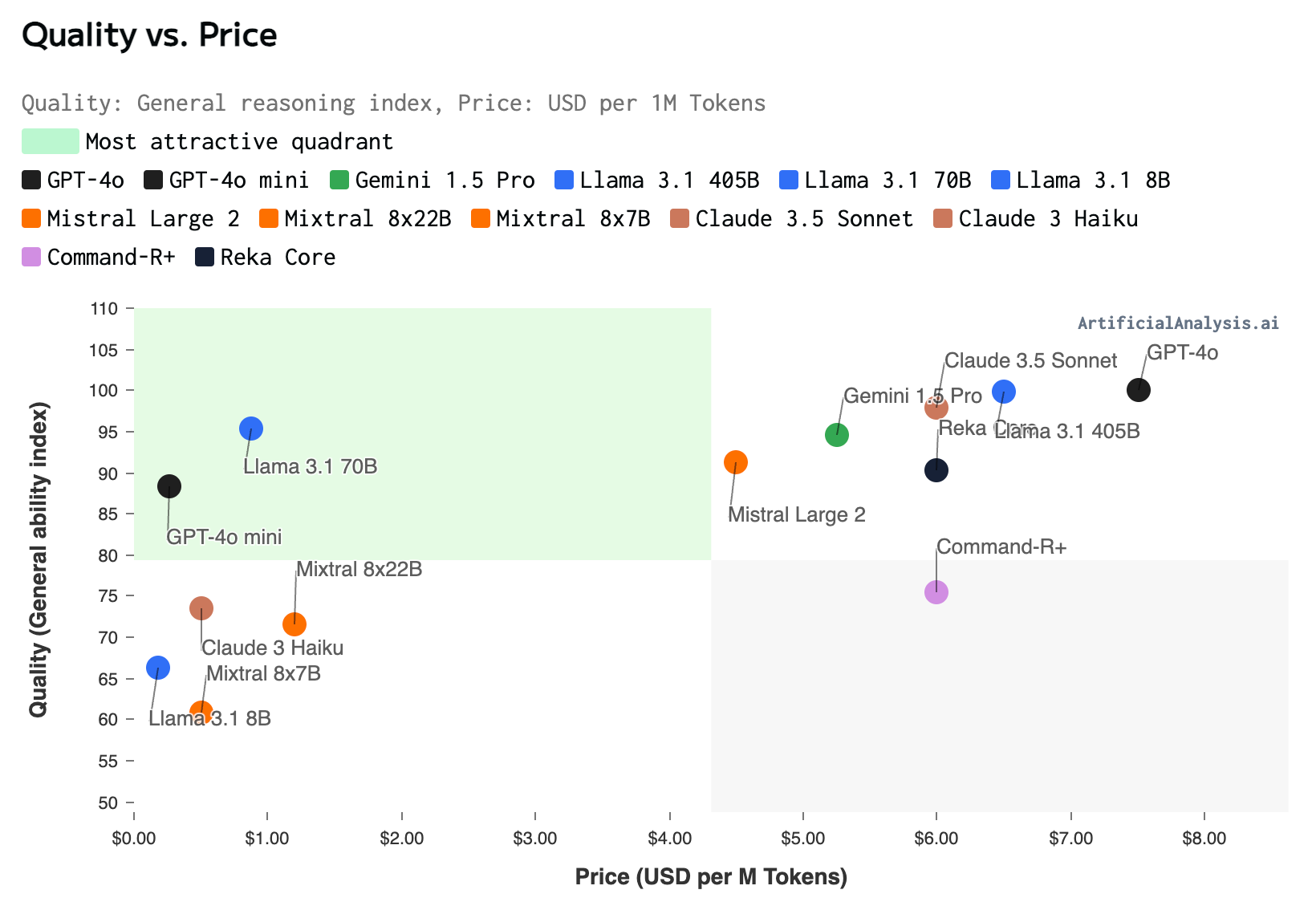
Think of these models as the general purpose foundation layer in the AI technology stack. For real-life decision about what models to use, developers need to balance between capability and cost. AI benchmarking Startup Artificial Analysis has comparison below that clearly illustrated the superior quality/performance of GPT4o-Mini and Llama 3.1 70B. Models in the green quadrant are the most attractive.
2. xAI Turns On Memphis AI Supercluster with Energy Efficiency Innovations
Energy consumption in AI training and inference has been a hot topic in boardroom discussions. Innovations help address the problem. xAI’s announcement about the new Memphis supercluster utilizing 100,000 liquid-cooled NVIDIA H100 GPUs highlights some advancements in high-performance computing and AI training infrastructure. For example, liquid cooling solutions could reduce AI data center power usage by up to 40% vs traditional air-flow solutions.
3. New Kid on the "Search” Block: SearchGPT from OpenAI
OpenAI announced the prototype of its highly anticipated search product: Search GPT. It combines internet search and the OpenAI GPT models to provide relevant answers and insights with citation. You can join the waitlist in your ChatGPT account. Early user feedback is positive. OpenAI’s SearchGPT is a credible challenger to Google and Perplexity, the Verge reports. OpenAI’s content agreement with major news media such as New York Times, might give them an edge over Perplexity in including high quality sources. Perplexity’s business model of building on top of third-party AI models gives them flexibility to switch but might sacrifices costs and speed vs a vertically integrated one. It is too early to evaluate and I look forward to the future of search.
4. Scientists Warn “AI Model Collapse” and Some Disagree
Nature published a paper titled "AI models collapse when trained on recursively generated data". The scientists investigate the phenomenon of "model collapse" in generative AI models, when AI models are trained on data generated by other AI models rather than human-generated data. They find that this recursive training leads to a degenerative process where models progressively lose information about the true underlying data distribution. This process, termed "model collapse," results in models forgetting improbable events and converging to a distribution with reduced variance, ultimately misperceiving reality. Tech Crunch questions if AI is eating its own tail when our internet has more and more AI generated data in the future. The image below illustrates how dog breeds in real images might eventually become the same in the ‘model collapse’ scenario.

Some researchers and investors disagree with the pessimism. Guido Appenzeller, a16z investor on AI & infrastructure and ex-CTO at Intel and VMWare, believes the scenario described is a research lab type of improbable one. The future AI model training data will always include the human generated data from our past and the synthetic data won’t replace real data. Under this scenario, the model collapse is far less likely. The debate continues.
The Case for Open Source AI, Revisited

In previous newsletters, I highlighted the potential for open source AI models to match the performance of closed source models, offering benefits like lower costs, transparency, and greater customization potential. With Meta's release of the Llama3 405B model, this prediction is becoming a reality. This open, frontier-capability large language model (LLM) is a significant milestone, earning praise from the AI community.
"It is the first time that a frontier-capability LLM is available to everyone to work with and build on." - Andrej Karpathy, co-founder and former researcher of OpenAI
Despite this progress, misconceptions about open source AI models persist:
Addressing Misunderstandings
1. Safety Concerns: Some believe open source models are less safe than closed source ones like OpenAI's GPT-4. However, open source models can be equally safe, if not safer, due to their transparent development processes and community scrutiny.
2. Security Threats: There is concern about these models falling into the wrong hands. Yet, openness can enhance detection and mitigation of misuse, as the community can collectively address potential threats.
3. Source of Capital Questions: The sustainability of open source development is often questioned due to the high investments required. However, the history of open source software shows that ecosystems form around these projects, driving innovation and providing satisfactory returns on investment.
Unique Advantages of Open Source Models
Open source models offer unique advantages for businesses:
Data Privacy: Open source models allow for fine-tuning without sharing data externally, which is crucial for businesses handling sensitive information.
Customization:Businesses can tailor these models to specific needs, leading to more effective AI solutions.
You may notice a concept frequently mentioned when people talk about the potential of open source AI: model distillation. Here's a non-technical guide:
AI Model Distillation 101: A Guide for Business Leaders
AI Model Distillation is a process that creates a more efficient, compact version of a large, complex AI system. Think of it as transferring the essential knowledge from a highly experienced executive to a more junior employee who can handle specific tasks efficiently.
Main Benefits of AI Model Distillation
Specialization: Distilled models excel at specific tasks while requiring less computational power.
Efficiency: It streamlines complex processes, retaining only the essential parts.
Accessibility: Smaller models can run on less powerful hardware, expanding deployment options.
Cost-Effectiveness: Using distilled models can reduce operational costs in AI deployment.
Why It Matters to Business Leaders
By leveraging distilled models, companies can significantly accelerate their decision-making processes. These streamlined models provide quicker responses, enabling leaders to act swiftly in dynamic business environments. Moreover, the compact nature of distilled models opens up new possibilities for deployment. They can be integrated into a wide array of devices, from smartphones to IoT sensors, enhancing operational flexibility across your organization.
One of the most tangible benefits comes in the form of cost savings. Distilled models, with their reduced computational requirements, can lead to substantial cuts in infrastructure expenses. This makes advanced AI capabilities more accessible, even for businesses with limited resources.
Perhaps most importantly, these models offer a high degree of customization. They can be fine-tuned to address the specific needs of your business, whether that's improving customer service, optimizing supply chains, or enhancing product recommendations. This tailored approach ensures that you're not just adopting AI, but adapting it to serve your unique business objectives.
A real-world example: Consider distilling a large language model into a specialized version excelling at customer service interactions for your specific industry. It's not as broadly capable but faster, more efficient, and potentially more effective for your specific needs.
AI model distillation makes artificial intelligence more practical, efficient, and accessible for businesses, allowing you to harness advanced AI tailored to your needs, cost-effectively and easily implementable across your organization. It might requires more technical know-now currently but there are many companies working fast to create solutions for much easier implementations - think of it as MdaS, ‘model distillation as a service’ in the future.
Data Quality and AI: Embrace the Imperfection

Some experts urging boards to mandate the highest standards of data quality for AI initiatives. I believe this approach may not always be practical or necessary, particularly for companies whose primary focus is applying AI rather than developing AI models.
While high-quality data undoubtedly enhances AI accuracy, mitigates bias, and improves efficiency, an overly stringent approach to data quality can present significant challenges. The resources required to achieve and maintain pristine data can be prohibitive, especially for smaller businesses or those new to AI implementation. Here is a more nuanced strategy:
Utilize existing data: Many AI applications can derive value from imperfect datasets.
Implement continuous improvement: Enhance data quality progressively alongside AI deployment.
Prioritize strategically: Focus on refining critical data elements for specific use cases rather than pursuing across-the-board perfection.
Leverage AI for data enhancement: Employ machine learning techniques to improve data quality, creating a positive feedback loop.
Have human in the loop: People with deep understanding of the private data and business objectives can identify problems and areas for improvement.
To implement this balanced approach, consider the following tactics for improving data quality:
Establish robust data governance policies and clear ownership
Implement automated data validation and cleansing processes
Conduct regular audits and updates of data sources
Invest in comprehensive employee training on data best practices
Utilize data quality tools to monitor and enhance data integrity
Create feedback mechanisms with AI systems to identify and rectify data issues
The key lies in striking the right balance. While a certain level of data quality is essential to avoid misleading or harmful outcomes, the pursuit of perfect data should not become a board-level request for executives at most companies. Different AI applications may have varying tolerances for data imperfections.
By adopting a pragmatic approach to AI implementation, businesses can lower barriers to entry while simultaneously working towards improved data practices. Begin with available data, focus on incremental enhancements, and prioritize quality in areas of greatest impact.
One More Thing: AI Fatigue

We hate to admit it as AI enthusiasts but it is true - we are also feeling the fatigue from many quick-to-become-cliche AI advice, dizzying AI product launches, still-lagging frameworks for trusted and secure AI systems, and the flooded inbox of AI-generated messages.
With the Paris Olympics on TV and summer heat in the air, it is a good time to slow down and think about the ‘why’ behind your AI pursuits - what are some business and personal goals you want to achieve? Starting with 'Why' helps to prioritize your AI strategy and ensure your investments will create tangible business value in the future. AI will be here for the long run, but we can certainly take a break to shake off our AI fatigue.
I am visiting my parents for the next few weeks. In caring for loved ones, the highly-capable AI robots couldn’t be here fast enough. This newsletter will return to the usual schedule after August 17. See you then.
Joyce Li